DeepSeek-R1本地部署指南
春节期间,Deepseek以其卓越性能赢得众多技术爱好者的关注。用户评价褒贬不一,但国际巨头的震惊足以证明其非凡之处。若你想在本地部署该模型,探索其强大功能,以下指南将为你提供详细指导。本文将介绍Windows和Mac双平台的部署流程。
一、基础环境搭建
安装Ollama
下载Ollama:
访问Ollama官网 ,根据你的操作系统(Windows、Mac或Linux)下载相应安装包。
以Mac和Windows为例,
安装验证:
安装完成后,在终端输入<font style="color:rgb(26, 32, 41);">ollama -v</font>验证安装是否成功。正确安装将显示版本号。
如何打开终端:
Mac:找到终端工具。
Windows:使用Win+R输入cmd。

然后检查
代码语言:javascript
代码运行次数:0
运行
AI代码解释
ollama -v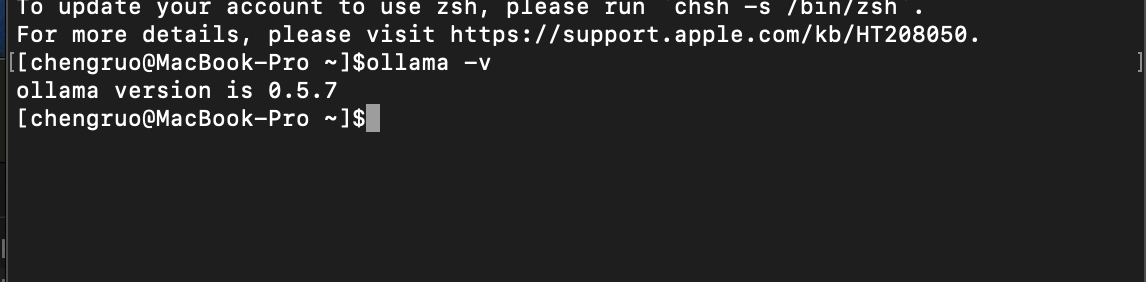
下载完成后,按照安装向导的提示逐步完成安装。在安装过程中,Ollama 服务会自动在电脑后台运行。
二、模型部署
选择模型版本:
打开Ollama模型库,选择适合自己电脑硬件的DeepSeek-R1模型版本(1.5B、7B、32B等)。
以下是本地部署 DeepSeek 系列模型(1.5B、7B、8B、14B、32B)在 Windows、macOS、Linux 三个平台的最低和推荐硬件配置指南。配置需求主要基于模型的显存(GPU)、内存(RAM)和计算资源需求,同时考虑不同平台的优化差异。
通用配置原则
模型显存占用(估算):
每 1B 参数约需 1.5-2GB 显存(FP16 精度)或 0.75-1GB 显存(INT8/4-bit 量化)。
例如:32B 模型在 FP16 下需约 48-64GB 显存,量化后可能降至 24-32GB。
内存需求:至少为模型大小的 2 倍(用于加载和计算缓冲)。
存储:建议 NVMe SSD,模型文件大小从 1.5B(约 3GB)到 32B(约 64GB)不等。
分平台配置建议
以下按模型规模和平台分类,提供 最低配置 和 推荐配置。
1.5B 模型
平台 | 最低配置 | 推荐配置 |
|---|---|---|
Windows | - CPU: Intel i5 / Ryzen 5 | - CPU: Intel i7 / Ryzen 7 |
- RAM: 8GB | - RAM: 16GB | |
- GPU: NVIDIA GTX 1650 (4GB) | - GPU: RTX 3060 (12GB) | |
macOS | - M1/M2 芯片(8GB 统一内存) | - M1 Pro/Max 或 M3 芯片(16GB+) |
Linux | - CPU: 4 核 | - CPU: 8 核 |
- RAM: 8GB | - RAM: 16GB | |
- GPU: NVIDIA T4 (16GB) | - GPU: RTX 3090 (24GB) |
7B/8B 模型
平台 | 最低配置 | 推荐配置 |
|---|---|---|
Windows | - CPU: Intel i7 / Ryzen 7 | - CPU: Intel i9 / Ryzen 9 |
- RAM: 16GB | - RAM: 32GB | |
- GPU: RTX 3060 (12GB) | - GPU: RTX 4090 (24GB) | |
macOS | - M2 Pro/Max(32GB 统一内存) | - M3 Max(64GB+ 统一内存) |
Linux | - CPU: 8 核 | - CPU: 12 核 |
- RAM: 32GB | - RAM: 64GB | |
- GPU: RTX 3090 (24GB) | - 多卡(如 2x RTX 4090) |
14B 模型
平台 | 最低配置 | 推荐配置 |
|---|---|---|
Windows | - GPU: RTX 3090 (24GB) | - GPU: RTX 4090 + 量化优化 |
- RAM: 32GB | - RAM: 64GB | |
macOS | - M3 Max(64GB+ 统一内存) | - 仅限量化版本,性能受限 |
Linux | - GPU: 2x RTX 3090(通过 NVLink) | - 多卡(如 2x RTX 4090 48GB) |
- RAM: 64GB | - RAM: 128GB |
32B 模型
平台 | 最低配置 | 推荐配置 |
|---|---|---|
Windows | - 不推荐(显存不足) | - 需企业级 GPU(如 RTX 6000 Ada) |
macOS | - 无法本地部署(硬件限制) | - 云 API 调用 |
Linux | - GPU: 4x RTX 4090(48GB 显存) | - 专业卡(如 NVIDIA A100 80GB) |
- RAM: 128GB | - RAM: 256GB + PCIe 4.0 SSD |
平台差异说明
Windows:
依赖 CUDA 和 NVIDIA 驱动,推荐使用 RTX 30/40 系列。
大模型(14B+)需借助量化或模型分片技术。
macOS:
仅限 Apple Silicon 芯片(M1/M2/M3),依赖 Metal 加速。
模型规模超过 14B 时性能显著下降,建议量化或云端部署。
Linux:
支持多 GPU 扩展和高效资源管理(如 NVIDIA Docker)。
适合部署大型模型(14B+),需专业级硬件。
注意事项
量化优化:使用 4-bit/8-bit 量化可大幅降低显存需求(如bitsandbytes[6])。
框架支持:优先选择优化好的库(如 vLLM、DeepSpeed、HuggingFace)。
散热:长时间推理需确保散热(建议风冷/水冷)。
建议根据实际需求选择硬件,并优先在 Linux 环境下部署大模型。
(二)顺利下载与稳定运行
确定适合自己电脑配置的模型版本后,就可以开始下载和运行模型了。打开终端或 CMD 命令窗口,输入对应的运行指令:
若选择 1.5B 版本,输入 ollama run deepseek-r1:1.5b 。
若选择 7B 版本,输入 ollama run deepseek-r1:7b 。我 Mac 选择的是这个。
若选择 8B 版本,输入 ollama run deepseek-r1:8b 。
若选择 32B 版本,输入 ollama run deepseek-r1:32b 。